Zaman Serisi ile Getiri Tahmin Modeli Oluşturma 1-Eviews ile Uygulama

Bu yazıda, doktora eğitimim sırasında almış olduğum Finansal Ekonometri dersinde hocam Prof. Dr. Burç Ülengin’den öğrendiğim teorik bilgi ve pratik uygulamayı, seçilen hisse senedi için örnek bir uygulamanın adım adım nasıl yapılacağı anlatılıyor. Bu yazının amacı, hisse senetlerine ait getirilerin nasıl tahmin edileceğini (linear model ile) göstermektir. Yazıda, bir getiri tahmin modelini kurabilmek için nasıl bir algoritma (prosedür) izleneceği de özetlenmektedir. Uygun bir model kurabilmek için gerekli olan kontrol ve testlerin nasıl yapılacağı ve elde edilen bulguların nasıl yorumlanacağı kapsam içerisindedir. Bu yazıda zaman serisi modellerinden ARIMA üzerinde duruluyor. Veriye uygun ARIMA modelinin kurulup kurulamayacağı araştırılıyor. Bu modellerin kurulmasında ve ilgili analiz ve testlerin yapılmasında Eviews paket programından yararlanılıyor. Aşama aşama verinin nasıl inceleneceği ve nasıl transformasyon yapılacağı, ilgili istatistiki ve model testlerinin nasıl yapılacağının ve tüm bu analizlerden elde edilen sonuçlara göre ARIMA modelini nasıl inşa edileceği detaylı bir şekilde anlatılıyor. Ayrıca, gerekli olması halinde getiri modellenmesine yardımcı olacak varyans modellemesinin de nasıl yapılacağı anlatılacaktır.
Bir finansal varlığın doğrusal getiri tahmin modelini kurabilmek için izlenmesi gereken adımları (model kurma algoritması) aşağıdaki gibi tarif etmek mümkündür.
- Ham verinin temel istatistiki incelemelerinin ve yorumlarının yapılması (outlier, yapısal kırılma, trend vb.) ve çıkarımların belirlenmesi
- Doğal logaritmalı verinin temel istatistiki incelemelerinin ve yorumlarının yapılması (outlier, yapısal kırılma, trend vb.) ve çıkarımların belirlenmesi
- Autocorrelation ve partial autocorrelation değerlerinin incelenmesi (trend var mı, AR ne olabilir, Integrated seviyesi ne olabilir, MA ne olabilir)
- Unit root testinin yapılarak verinin stationary olup olmadığının test edilmesi (trendin netleştirilmesi, level da mı, first difference ta mı, second difference ta mı stationary)
- Önceki adımlar ışığında (veya auto ARIMA selection ile) AR ve MA laglerinin belirlenmesiyle model kurulması
- Kurulan modelin uygun olup olmadığının (katsayılar istatiki olarak anlamlı mı, residuallar white noise mu vb.) değerlendirilmesi
- Eğer ihtiyaç var ise varyans modellemesinin yapılması (ihtiyaç olması durumunda ilgili yazıda nasıl modelleme yapılacağı detaylandırılacaktır)
Getiri tahmin modelini oluşturma sürecinin anlatımı, bir yazı dizisi şeklinde planlanmıştır. İlk yazı, verinin quick analizi, transformasyonu ve verideki oto korelasyon ve kısmi korelasyon çıkarımlarını kapsıyor. Bu yazıdan sonra gelecek yazılar, ARIMA modeli kurabilmek için gerekli testlerin yapılması (unit root test vb.) ve sonrasında elde edilen bilgiler ışığında ARIMA modelinin kurulması olarak üç yazı şeklinde planlanmıştır. Gerekli olması halinde varyans modellemesinin de dahil edileceği dördüncü bir yazı da bu yazı dizisine eklenebilir.
1- Verinin belirlenmesi ve analizi
İlk yazı, seçilen finansal varlığa ait verinin finansal ekonometri modelleme kurallarına uygunluğunun incelenmesi, yorumlanması ve gerekli kontrollerin yapılmasıyla oluşmuştur. Bir finansal varlık verisi incelenirken ilk olarak, verinin temel istatistiki bilgi sağlayan plot, histogram, box-plot gibi grafikler çizdirilir ve ilgili veriler (ortalama, medyan, standart sapma vb.) hesaplanır. Bunun temel amacı, veriye ilk bakıldığında nasıl bir davranış sergilediğini çıplak gözle tespit edebilmek (outlier var mı, trend var mı, sezonsallık var mı vb.) ve sonrasında veriye özgü işlemleri yapmaktır.
Üzerinde çalışacağımız veri Palantir Technology Inc. hisse senet fiyatlarıdır. Verinin dönemi 1–1–2021 ile 11–4–2022 olup günlük kapanış değerleri üzerinden veri analize konu oluyor. Veri, Yahoo finance’dan elde edilebilir. Buradan elde ettiğiniz veriyi bilgisayarınıza indirmeniz gerekiyor. Daha sonra Eviews’tan yeni bir workfile oluşturulmalı. File →New →Workfile adımlarını izleyerek workfile oluşturabilirsiniz.

Yeni bir workfile açarken bazı bilgilerini girmeniz program beklenir. Verinin çalışma sıkılığı (örneğimizde 7 günlük veri) ve dönemi (1/1/2021–4/11/2022) doldurulmalı.

Bilgisayarınıza inen veri (csv dosyasını) File →Import →Import from file ile Eviews’a yüklenmeli.

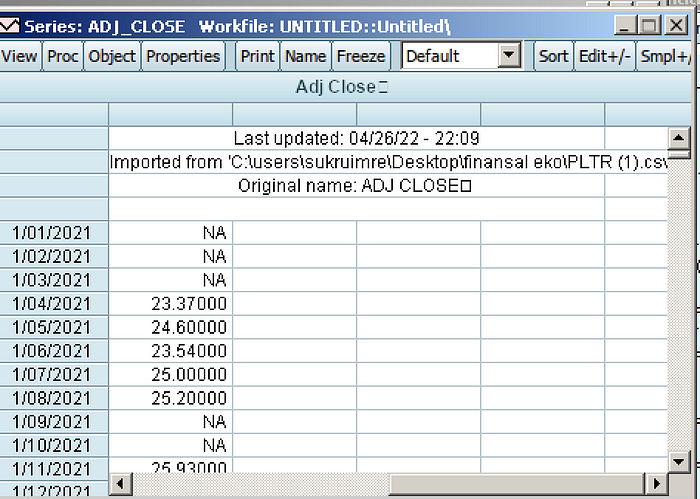
Sonrasında çalışma alanında aşağıdaki gibi bir görüntü oluşur. Burada, analiz ve modelleme için adj_close (gün sonu kapanış değeri) verisi dikkate alınıyor.

Bu veriye çift tıkladıktan sonra ilk analizleri yapabilir. Çift tıkladıktan sonra elde edeceğimiz görüntü aşağıdaki gibidir.
Herhangi bir veriyi analiz etmeye temel istatistiki göstergelerin olduğu bilgilleri içeren adımlardan başlamak gereklidir. Bunu gerçekleştirebilmek için ilk adım plot, histogram ve box-plot çizdirilmesidir. Bu üç araç, veri hakkında genel görüntüyü sunmaktadır. İlk olarak kapanış fiyat değerlerinin zamana göre plotu çizilir. Bunun için Açtığınız veri dosyasında View →Grapha tıklamak gerekmektedir.

Daha sonra, hangi graph türünü çizdirilmek isteniyorsa seçilmelidir. Seçenekler arasında, histogram, line, boxplot ve bunlar gibi pek çok grafik bulunuyor. Plot çizdirilmek istendiğinden, line graph olarak işaretlenir ve grafik çizilir.

Aşağıda veriye ait fiyat grafiğini zamana göre çizilen grafiği görülebilir. Şekil 1'de günlük kapanış değerlerinin ilk dönemlerde yüksek seyrettiği, sonrasında ise ani düşüşle dalgalı devam ettiği görülmektedir. 2021 dördüncü çeyrekten 2022 birinci çeyreğin ortasına kadar düşüş trendi göstermiştir. Aynı çeyreğin sonlarına doğru artış göstermektedir. Bazı değerlerde ise noksanlıklar söz konusudur. 2021 birinci çeyrekte outlier değerler söz konusu olabilir. Belirli bir süre birden yükselip seyrine devam ettikten sonra fiyat düşüş trendine geçmiş ve aşama aşama düşmüştür. 2021’in dördüncü çeyreğinin ortalarında düşüş trendine geçerek seyir bandını aşağıya çekmiştir. Bu durum veride yapısal kırılmaya (structural break) olabileceğini ifade eder. Yapısal kırılmadan kasıt, verinin artık önceki seviyelere çıkamaması (veya inememesi) demektir. Artık veri başka bir seviyede gerçekleşmektedir denilebilir. Yani, bu tip veriler için modelleme yaklaşımı değişebilir. Yapısal kırılmanın öncesindeki veri atılarak bir modelleme yapılabilir veya yapısal kırılma öncesi için farklı bir model, sonrası için de farklı bir model kurulması gerekebilir. Bu yüzden, veride yapısal kırılma olup olmadığı kritiktir (ilerleyen yazılarda yapısal kırılma testlerini uyguluyor olacağız).

Verinin histogramı çizdirmek için View → Descriptive Statistics & Tests →Histogram and Stats yolunu takip etmek gerekmektedir.

Aynı verinin histogramı Şekil 2'de gösterilmiştir. Bu şekle göre, fiyat ortalaması 21,88 ve standart sapması 5.58 bulunmuştur. Çarpıklık değeri -0,11 ve basıklık değeri 3,18 olarak hesaplanmıştır. Veri orta fiyat değerlerinde yığılma gösterirken, aynı zamanda sol kuyrukta da yığılma ve gözlemler söz konusudur. Sağ kuyrukta az sıklıkta gözlemlese de veriler bulunmaktadır. Kuyruktaki bu değerler veride outlier değerler olabileceğine işaret etmektedir. Normal dağılım çarpıklık (0)ve basıklık (3) değeri dikkate alındığında, verinin normal dağılıma uygun bir dağılım olduğu görülmektedir. Jarque-Bera testi verinin normal dağılıp dağılmadığını test etmektedir. H0 hipotezi verinin normal dağıldığını ifade ettiğinden, Jarque-Bera olasılık değeri 0,55 olup %95 güven aralığında test etmemiz durumunda bu değer 0,05'ten büyük olduğu için H0 hipotezi reddedilemez sonucunu çıkarabiliriz. Yani, veri normal dağılıyor diyebiliriz.

Yukarıda histogram için yapılan yorumlarda veride outlier değerler olabileceğini, dolayısıyla bir box-plot çizilmesi gerektiğini ifade ediliyor. Box-plotu çizdirebilmek için plot çizdirme yolunu takip ederek grafik seçeneğinden box-plotu seçmek yeterli olacaktır.

Şekil 3'te veriye ait box-plotu görebilirsiniz. Bu şekle göre, outlier değerler gözükmektedir. Yani, 2021'in ilk çeyreğinde (bakınız Şekil 1) veride görülen yükselişlerin bazılarının outlier olduğu anlaşılmaktadır.

Fiyat verisi küçükten büyüğe sıralandığındaki hali ile verinin ilk %25'i 10$ ile 19$ arasında geniş bir aralıkta yer almaktadır. Verinin ikinci %25'i ise 19$ ile 24$ arasında olup daha ilkine göre daha dar bir aralıkta yer almaktadır. Verinin üçüncü %25'lik topluluğu ise 24$ ile 25$ arasındadır. Verinin bu kısmı en dar aralıktadır. Ayrıca, fiyat verisinin %75'nin 25$’ın altında olduğu söylenebilir. Son %25'lik dilimi ise 25$ ile 40$ arasındadır.
2- Verinin transformasyonu
Finansal ekonometride çalışılan veri log getiri verisidir. Bunun nedeni, basit getiri hesabında (simple return), getiriler 0 ile +sonsuz arasında olmasıdır. Bu durum getirilerin normal dağılmamasına neden olur. Getiri modellemesinde kullanılacak verilerin normal dağılıma sahip olması (ya da yakın olması) beklenir. Örneğin, 100 TL yatırdığınız bir hisse senedinde getiriniz, hisse senedinin %100 değer kaybetmesi durumunda elde kalan para 0 TL (%0 getiri oranı) olacaktır. Yani, tüm yatırılan para kaybedilir. Bunun ötesinde bir değer yoktur. Böyle hesaplanan basit getirinin minimum değeri %0 olur. Tam tersi durumda ise yatırdığınız 100TL’nin karşılığı hisse senedinin değerlenmesiyle 120TL veya 150TL olması durumunda, getiri 20 TL ve 50 TL olacaktır. Getiri oranları ise %20 ile %50 olup hisse senedinin daha da değerlenmesiyle sonsuza giden bir getiri oranı teorik olarak mümkündür. Log getiri değerleri ise teorik olarak -sonsuz ile +sonsuz arasında değer alabilmektedir. Bundan dolayı, getiri modellemelerinde log return kullanılıyor.
Hisse senedinde getiri modellemesini inşa edebilmek için ilk olarak getiri verisinin hesaplanması gerekmektedir. Normalde bir hisse senedinin getirisi aşağıdaki formülle hesaplanır. Bu formüle göre, bugünkü fiyatı (t. dönem)120 TL ve dünkü fiyatı (t-1. dönem)100 TL olan hisse senedinin getirisi %20 olarak hesaplanır.

ln’lı getirinin hesabında aşağıdaki gösterilen doğal logaritmalı formül kullanılır.

Bu formüle göre, t. döneme ait hisse senedi fiyatının bir önceki döneme (t-1. dönem) bölünerek ln’in alınması t. dönemdeki ln’li getiriyi vermektedir. Finansal verilerde genellikle ln (natural logarithm) dönüşümü yapılarak modellemeler yapılır. Özellikle yüksek frekanslı (günlük, dakikalık veya seans içi veri) bir veride yapılacak getiri (return) modellemesinde fiyat yerine ln’li getiri verisi hesaplanır. Yazı içerisinde kullanılan logaritmalı veri söylemi, ln alınmış fiyat verilerini temsil etmektedir.
Şimdi, ham fiyat verisinin ln’nin Eviews’ta nasıl alındığını gösterelim. Komut satırına genr log_palantir_close=log(adj_close) komutu yazılarak Enter’a basılır. genr fonksiyonu üreteceğiniz serinin ismini girdi alır. Eviews’taki log() fonksiyonu da serinin ln’nin alınmasını sağlamaktadır.

Bu komutu çalıştırdıktan sonraki görüntü aşağıdaki gibidir. Oluşturulan seriye çift tıklanarak veriye ulaşabilir ve tanımlayıcı istatistiki analizleri yapılabilir.

Ham veri için uygulanan adımları ln’li veri için de yapılır. Şeki 4 grafiğine bakıldığında veri daha kompak (Şekil 1'e kıyasla) bir yapıya geçmiştir. Bir diğer deyişle, verinin dalgalanma boyutu, ham veriye göre daha dar alanda gerçekleşmiştir. Ham veriden farklı olarak 2021 birinci çeyreğinden dördüncü çeyreğe kadar ki veri, daha düşük dalgalanma gerçekleştirmiştir. Bu zaman aralığında yer yer düzenli inişler ve hemen ardından ani yükselmeler kaydetmiştir. Bazen yükselme trendine geçmiş sonrasıda ani düşüşle stable devam etmiş sonrasında yeniden yükselme tredine geçmiştir. Bu durum bu zaman aralığında 3–4 kere tekrarlanmıştır. 2021’in dördündü çeyreğin ortalarından 2022’in birinci çeyreğine kadar düşüş trendi göstermiştir. Buradan sonra dalgalanma boyutu artmış ve inişli çıkışlı bir yol izlemiştir. Burada bir yapısal kırılma söz konusu olabilir.

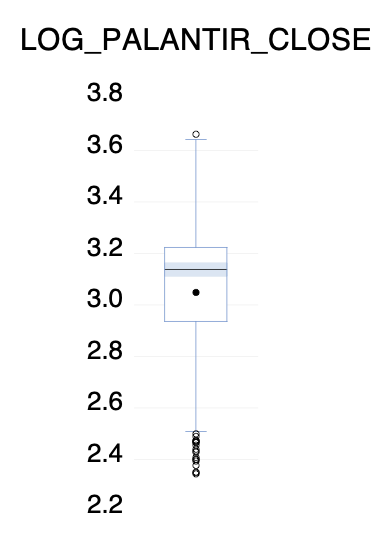
Şekil 5 histogram grafiğine bakıldığında, ham veride olduğu gibi sol uç değerleri sağ uç değerlerine göre daha fazla gözlem içermektedir. Jarque-Bera hipotez sınaması dikkate alındığında, olasılık değeri 0.05’ten küçük olduğu gözlemlenmektedir. Bu durum verinin normal dağılmadığını sonucunu doğurmaktadır.

Son olarak Şekil 6'da box-plot dikkate alındığında, hem üst hem alt değerlerinde outlier olduğu görülmektedir.
Oluşturulan lnli veri ile ham verinin bir arada bulunduğu grafik Şekil 7'de gösterilmektedir. Yukarıda yapılan yorumlara paralel olarak, lnli verinin fiyat verisine göre daha dar alanda bir dalgalanma gerçekleştirdiği görülmektedir. Fiyat verisindeki ani yükseliş ve düşüşleri lnli veri daha smooth bir şekilde gerçekleştirmektedir.

3- Oto korelasyon ve Kısmi oto korelasyon Kontrolü
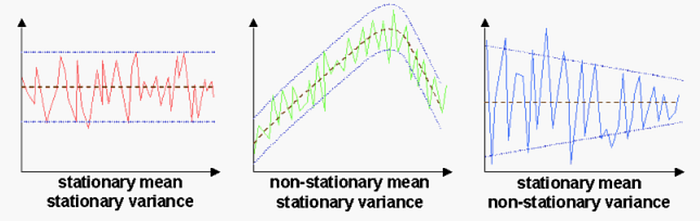
Finansal getiri tahmin modelinin kurulmasında çalışılacak veri durağan (stationary) olmalıdır. Verinin stationary olmasından kasıt, zaman içerisinde verinin ortalama ve varyans değerlerinin aynı kalmasıdır. Şekil 8'deki ilk grafik, ortalama ve varyans açısından stationary olan bir seriyi göstermektedir. Veride yer yer inişler çıkışlar olmasına rağmen zaman içerisinde bir sınır içerisinde kalmıştır (stationary varyans) ve belirli bir değer etrafında (stationary ortalama) dalgalanmıştır. Diğer iki grafikte ise non-stationary örnekler gösterilmiştir. Ortadaki grafikte veri belirli bir sınırda hareket ederken, ortalama değeri önce yükseliş trendi göstermiş ve sonrasında düşmüştür. Son grafikte ise ortalama zaman içerisinde sabit kalırken, verinin bulunduğu bant zaman geçtikçe daralmıştır. Bu iki grafik, verinin stationary olmadığını göstermektedir.
Verinin stationary olup olmadığını ve veride trend olup olmadığını belirleyebilmek için oto korelasyon ve kısmi oto korelasyon analizi yapılmalıdır. Eğer veri trendli ise ortalama bakımından veri stationary değil denilebilir.
Oto korelasyon ve kismi oto korelasyonlar, hangi seviyedeki verinin modellemede kullanılacağının kararına da yardımcı oluyor. Buradaki verinin kullanım seviyesi üç şekilde olabilir:
- level → logaritmalı veri

- first difference → logaritmalı veriler arasındaki 1 kere fark alınması

- second difference → logaritmalı verilerde alınan farkların farkının alınması

Verinin seviyesinin belirlenmesi ARIMA modellerinin integrated kısmına denk geliyor. Bu kısım, doğrudan logaritması alınan veriyle mi çalışılacak (level diye test ediliyor) yoksa veride fark almak gerekecek mi (first/second difference) bilgisini veriyor. Eğer veri levelda stationary çıkarsa, ARIMA’nın I değeri 0, first diffrence stationary çıkarsa I değeri 1 olarak belirlenir. I değeri belirlendikten sonra tahmin modeli geliştirme — AR ve MA seviyelerini belirmeye — sürecinde bu veriyle hareket edilecektir. Finansal verilerin çoğu first difference da stationary olmaktadır.
Eğer oto korelasyonlar ağır ağır azalır, kısmi oto korelasyonlar da ilk değerden sonra sıfıra yaklaşırsa veride trend vardır denilir (veride iki türlü trend olabilir: deterministik ve stokastik)
Oto korelasyonlardan stationary ve trend hakkında ilk sinyal alındıktan sonra, unit root test yapılarak verinin stationary olup olmadığını ve hangi trende sahip olduğuna karar veriliyor (bir sonraki yazı detaylandırılacak).
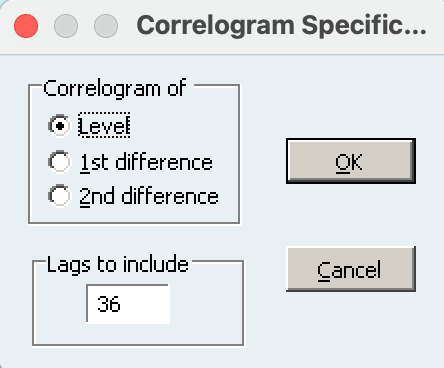
Logaritmalı veride — level veride — oto korelasyon ve kısmi oto korelasyon değerleri hesaplanmalıdır. Bu hesabı yapabilmek için Eviews’ta logaritmalı veri açıldıktan sonra View → Correlogram yolu izlenmelidir.

Daha sonra, açılan pencerede “level” seçilmeli ve OK tıklanmalıdır.
Yapılan işlemler sonrasında elde edilen sonuçlar aşağıda gösterilmiştir. Oto korelasyonlar ağır ağır azalması ve kısmi oto korelasyonların ilk değerden sonra ani düşüş göstermesi serinin trendli bir seri olduğunun göstergesidir. Trendli seri stationary olamayacağından logaritmalı veride model geliştirmesi yapılamaz sonucu çıkarılır. Bu yüzden, aynı işlemlerin first difference için de yapılıp kontrollerin sağlanması gerekir.
Ayrıca, Ljung-Box-Pierce istatistiğine (Q-istatistiği) bakılarak da serinin lagleriyle ilişkisi olup olmadığını anlamak mümkündür. Bu test istatistiği oto korelasyonların belirlenen lagler için korelasyonların aynı anda 0 olup olmadığını test eder. Örneğin, lag sayısı 5 olarak alındığında, ilk 5 oto korelasyonun aynı anda 0 olup olmadığı test edilir. Yani, eğer H0 hipotezi reddedilirse (olasılık değeri <0.05 → %95 güvenle), oto korelasyon katsayıları istatistiki olarak 0 değildir, 5 lag için hesaplanan oto korelasyonlardan en az biri 0'dan farklıdır. Dolayısıyla, seri geçmiş laglerden etkileniyor denilebilir.
Q-istatistiği kikare dağılımına karşılık gelen olasılığa göre test edilir. Bu bilgi ışığında, aşağıda logaritması alınmış verinin çizdirilen correlogramın sonuçları dikkate alındığında, tüm laglerdeki oto korelasyon katsayısı 0'dan farklı çıkmıştır çünkü tüm olasılıklar 0.05'ten küçüktür ve H0 hipotezi reddedilir. Level veri geçmiş laglerinden etkileniyor demektir. model kurabilmesi için verinin geçmiş değerlerinden etkilenmemesi yani white noise olması gerekmektedir.

Aynı işlemler yapılarak, “first difference”daki oto ve kısmi oto korelasyonlara ait correlogram sonucu aşağıda paylaşılmıştır. Bu correlogramın sonuçlarına göre, Q-istatistiğine ait olasılık değerleri dikkate alındığında tüm gözlemlerdeki olasılık 0.05’ten büyük olduğu için first difference white noise denilebilir. Yani, geçmişten gelen bir sinyal bulunmamaktadır. Ancak lag 4’te Q-stat olasılık değeri 0.142 olduğundan ve 0.05'e yakın bir değer olduğundan, bu lag modelin tahmininde sinyal verebilir. Model kurma aşamasında AR(4), MA(4) veya ARMA(4,4) denenmelidir sinyali alınıyor.

Sonuç olarak, first difference verisi ile model geliştirmeye devam edilecektir. Unit root testi yapılarak nihai yapı sağlamlaştırılacak ve yukarıda elde edilen çıkarımlarla model denemeleri yapılıp uygum tahmin modeli kurulacaktır. Bir sonraki yazıda, belirlenen verinin temel istatistiki incelemelerini, unit root testi ile hangi trende sahip olduğunu ve veride yapısal kırılma olup olmadığını belirleyecek adımlar anlatılacaktır.
Dr. Şükrü İmre







